还记得谷歌上个月推出的 AutoDraw 吗?这是一个能把你的随手涂鸦变成绘画的人工智能技术工具。谷歌也曾发布论文和博客介绍了其背后的技术,参见机器之心文章《谷歌官方揭秘 AutoDraw 人工智能绘画工具原理:让机器学会理解艺术》。实际上,AutoDraw 所用的技术基于谷歌先前的涂鸦实验「Quick, Draw!」。近日,谷歌发布了该项目背后的数据集,其中包含 5000 万张矢量画。机器之心对该项目的介绍文档进行了编译介绍。

数据集地址:https://github.com/googlecreativelab/quickdraw-dataset
数据集官网:https://quickdraw.withgoogle.com/data
Quick, Draw! 在线体验:https://quickdraw.withgoogle.com
AutoDraw 在线体验:https://www.autodraw.com
相关论文:https://arxiv.org/abs/1704.03477
Quick Draw 数据集是一个包含 5000 万张图画的集合,分成了 345 个类别,这些图画都来自于 Quick, Draw! 游戏的玩家。这些画都是加了时间戳的矢量图,并带有一些元数据标注,包括玩家被要求绘画的内容和玩家所在的国家。你可以在数据集官网浏览被识别出的绘画。
我们在这里将这个数据集共享给开发者、研究者和艺术家,以供探索、研究和学习。如果你使用这个数据集创造出了什么东西,请发邮件告知我们:quickdraw-support@google.com 或提交到 A.I. Experiments:https://aiexperiments.withgoogle.com/submit
请注意,尽管这个绘画集合中每一张都被审核过,但其中可能仍有不当内容。
原始的审核过的数据集
原始数据在 ndjson 文件中,并按类别进行了分割,按照如下格式:
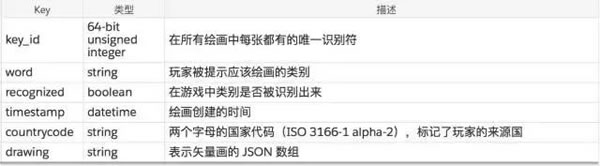
每一张包含一副绘画,下面给出了一个例子:
绘画数组的格式如下:
其中 x 和 y 是像素坐标,t 是自第一个点开始后的时间,单位:毫秒。x 和 y 是实数值,而 t 是整型值。因为用于显示和输入的设备各不相同,原始绘画的边框大小和点的数量可能有非常大的差异。
预处理后的数据集
我们已经对该数据集进行了预处理,并且将其分成了不同的文件和格式,以便人们能更快更轻松地下载和使用。
简化图文件(.ndjson)
我们对这些矢量图进行了简化,移除了时间信息,并且对数据进行了定位和缩放处理,得到了大小 256×256 的图像。该数据以 ndjson 的格式导出,带有与原始格式一样的元数据。简化过程如下:
1. 将绘画对齐到左上角,最小值为 0;
2. 均匀缩放绘画,最大值为 255;
3. 以 1 像素的间隔重采样所有的笔画;
4. 使用 Ramer–Douglas–Peucker 算法简化所有的笔画,设置其 ε 值为 2.0
二进制文件(.bin)
我们也提供了简化后的绘画和元数据的定制二进制格式,可用于高效的压缩和加载。examples/binary_file_parser.py 给出了如何用 Python 加载该文件的示例。
Numpy 位图(.npy)
所有简化过的绘画也都被转换成了 28×28 的灰度位图,保存为 numpy 的 .npy 格式。该文件可以通过 np.load() 函数加载。这些图像是从简化过的数据中生成的,但对齐的是绘画边框的中心,而非左上角。
获取数据
该数据集在谷歌云存储服务中,在 ndjson 文件中分类存储。请参阅 Cloud Console 中的文件列表,你也可以使用其他方法使用它(参阅:https://cloud.google.com/storage/docs/access-public-data)。
数据集分类
Raw files (.ndjson)
Simplified drawings files (.ndjson)
Binary files (.bin)
Numpy bitmap files (.npy)
Sketch-RNN QuickDraw 数据集
这些数据也被用于训练 Sketch-RNN 模型。该模型开源的 TensorFlow 应用将在 Magenta Project 上近期推出。了解该模型可参阅文章《谷歌官方揭秘 AutoDraw 人工智能绘画工具原理:让机器学会理解艺术》。数据存储在压缩文件.npz 中,这种格式适合输入进循环神经网络中。在这一数据集中 75000 个用例(70000 用于训练、2500 个用于验证、2500 个用于测试)在每个类别里随机选择,使用值为 2.0 的 epsilon 参数经过 Ramer–Douglas–Peucker 算法线简化处理。
许可证
这些数据由谷歌提供,使用 Creative Commons Attribution 4.0 International 许可证。
参与:吴攀、李泽南












