作为文字工作者,我每天都在跟搜索引擎打交道。
比如在写 Facebook 的财报新闻时,Google 可以告诉我它的实时股价、市值、近期高低点等非常有用的信息。
但其实,还有另一个工具比 Google 更好用,那就是 Wolfram Alpha。它比 Google 更进一步,可以用结构化的方式直接列出我可能需要的知识。
举个最简单的例子:我家带宽是 75Mbps (9.375MB/s),要下载一个100GB的文件需要多久?我可以直接用自然语言询问,Wolfram Alpha 不仅会告诉我答案,还会写出公式:
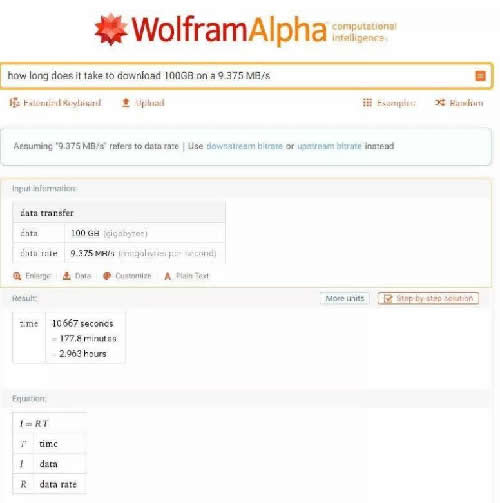
它不仅是一个数学工具,还是一个很好的知识聚合工具。比如最近电影《小丑》很火,如果我想写关于它的文章,上 Wolfram Alpha 一搜就能找到大量细节,包括并不限于影片信息、排名和票房等。
准确来讲,Wolfram Alpha 并非一个搜索引擎。它的官方定义叫做“计算式知识引擎”,可以用来回答那些没有公开答案,但是计算一下即可得到的问题。而且,它用结构化的方式去展现答案,而不是像搜索引擎那样,把链接一条一条列出来。
接下来介绍今天文章的主角:Magi,一个最近几天在我的技术圈朋友中间小有名气的工具。
Magi(网址 https://magi.com)看起来也像是一个搜索引擎:

但是只要玩上一次,就会发现,它和你印象中的所有搜索引擎都大不相同。
当我用它搜索词条“易烊千玺”时,得到了下面的结果。
首先,答案提供了对易烊千玺的几个关键描述,如“TFBOYS的成员”、“00后国民偶像代表”等。紧接着,它列出了关于词条主人的几乎全部的重要属性,包括由他出生年月、参演的影视作品、发表的音乐专辑等。
答案的结构化展现方式,和 Wolfram Alpha 颇有类似。
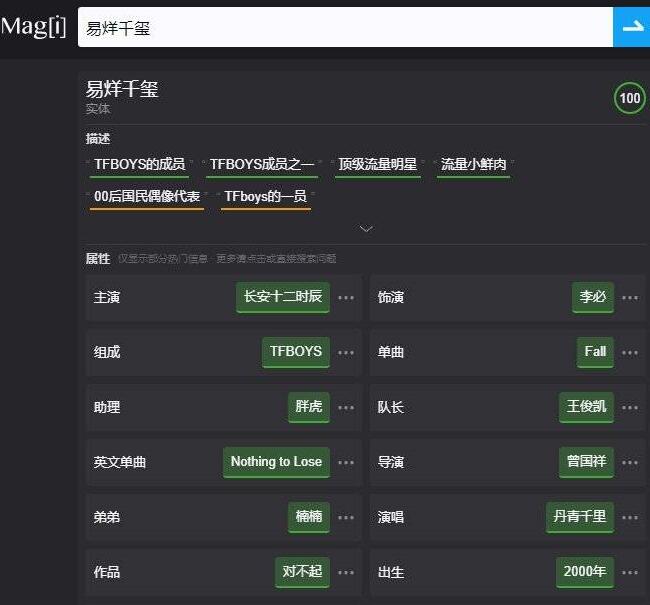
甚至连千纸鹤(易烊千玺粉丝代称)的应援色都答了出来
更有趣的是,magi.com 还答出了易烊千玺的几个近义项,比如他的昵称、代称和他所养的宠物等等。
有时候,Magi 还能给出一些令我忍俊不禁的结果……
输入了一下“新世纪福音战士”。答案的描述中有“业界有名的劳模”……
又搜了一下小岛秀夫,答案里的“专长”一项我也是醉了……
接下来搜了一下富坚义博。
可能因为职业生涯中大部分时间都在拖稿,magi.com 告诉我富坚的业余爱好是“画画漫画”……
当然,大部分时候 magi.com 给出的答案还是比较靠谱的。
搜索到的答案,每一条都会用以绿、黄、红三种颜色表示其可信度从高到低;在答案的右侧则会提供几条链接,用鼠标划过它们即可看到,答案是从哪个/哪几个具体的来源学习到的:
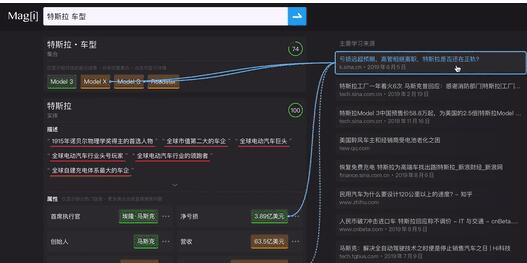
你会注意到,magi.com 的结果中,答案在正下方,链接跑到了右边,跟主流搜索引擎的用户界面完全是反的。
这就是 Magi 和主流搜索引擎最大的区别所在:链接对于它不是结果,答案才是。
这是因为 Magi 并非搜索引擎(尽管具有一些搜索引擎的功能)。它实际上是一个基于机器学习的知识引擎,能够检索和提取任何领域自然语言文本,将其中的知识提取出来,形成结构化的数据。
说得简单一点:
我们都知道,互联网上有着大量的,基于文本的信息,当中蕴藏着许多的知识。然而,计算机读不懂互联网上大部分的信息,因为这些信息往往不是以“性别:男”、“国籍:中国”这样的结构化形态,而是以自然语言的形态出现的。
比如,”埃菲尔铁塔的高度“是一个入门级的问题,因为早已有人整理出了正确的答案,写在维基百科和旅游网站上;但是想知道“埃菲尔铁塔的第二节电梯线路有多长”,就很难在搜索引擎上查到准确信息了。这是因为很少有人会把这些细节的数据,以结构化的方式记录在互联网上。
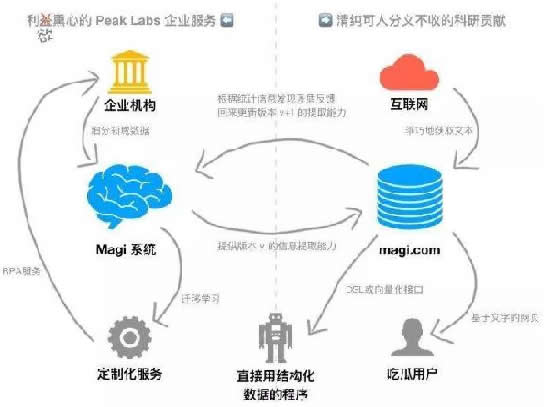
这就是 Magi 想要解决的问题:从开放领域的纯文本当中提取知识,并让其可解析、检索和溯源。
Magi 来自中国团队 Peak Labs,创始人季逸超在开发者圈子内也小有名气。2011年,还在北大附中读书期间,他就独自完成了猛犸浏览器 iOS 的开发。次年,他只用两天时间就完成了 Rasgueado,第一个支持划动手势控制光标位置的 iOS 输入法
2012年,季逸超创办了自己的公司,继续推动浏览器和输入法项目。目前,Peak Labs 主要精力都放在 Magi 项目上,专注于背后的技术,以及相关商业产品的开发。
Peak Labs 并没有计划将 Magi 和 Google、百度之类的主流搜索引擎相提并论。把 Magi 做成一个“搜索引擎”,主要是为了让公众有机会能够体验它背后的技术,感受它能够提供的价值。
即便如此,看起来很像搜索引擎的 magi.com,实力还是不容小觑。事实上,为了这个示范性质的产品,Peak Labs 并没有选择小聪明的方式,从其他搜索引擎抓取结果,而是从零开发了一套互联网搜索引擎。
”我们的结果的摘要比一般的搜索引擎都长,是的,我们是故意为之。这足以证明我们的结果不可能来自其他搜索引擎,“季逸超在官网上写道。
根据用户输入问题、关键词和表达式的不同,magi.com 可以用不同的方式来呈现答案——具体的呈现方式也展现了 Magi 系统的能力。
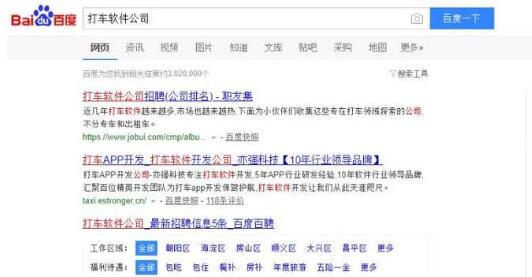
比如,输入“打车软件公司”,Magi 系统可以把它知道的所有手机叫车公司,以“集合”的方式列在答案里。
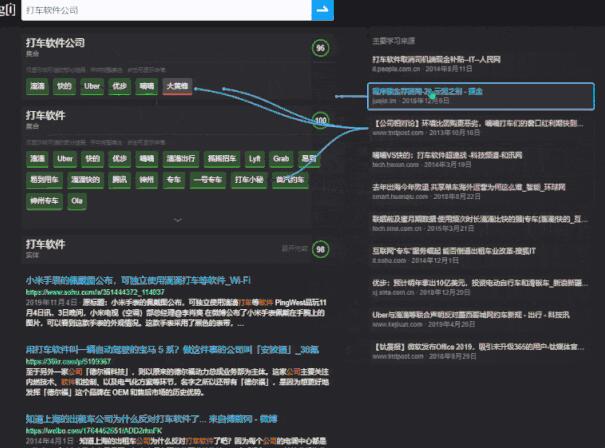
而在百度上,得到的结果如下。可以看到百度的知识图谱也提供了类似的结果,只是看起来有四、五年没有更新过了:
再比如,如果输入“八角 大料”,Magi 系统会发现这两个关键词其实是同一个东西,它就会以“断言”的形式给出答案。
magi.com 告诉我,八角和大料是“近义项”,是“又称”、“也称”的关系。
Magi 系统可以24小时不间断地进行学习。它的时效性也还算不错,Peak Labs 宣称实时新闻当中的知识,Magi 只需要 5 分钟就可以掌握,而且还可以采纳新的信息源进行交叉验证,实现自动纠错。
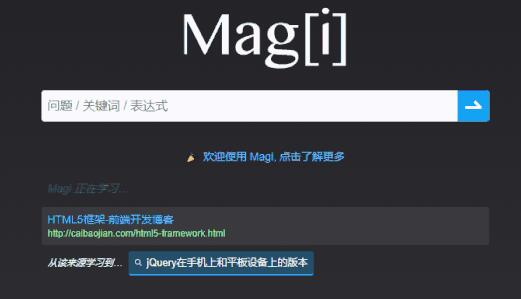
如果你在 magi.com 的首页停留一会,就能看到它当前正在学习的链接:
除了自主开发的全网规模搜索引擎以外,Peak Labs 还开发了基于注意力机制的神经信息提取系统,不依赖无界面浏览器的分布式抓取系统(爬虫程序 MagiBot),以及支持混合处理170多种语言的自然语言管道。
这四者结合在一起,才是 Magi 系统的全貌。
Peak Labs 在官网指出,目前的 Magi 技术还没有完全成熟。
确实如此。目前通过 magi.com 可以观察到一些问题,比如很多可以在主流搜索引擎中轻易找到的答案,magi.com 给不出来(通常是因为它还没有学到);
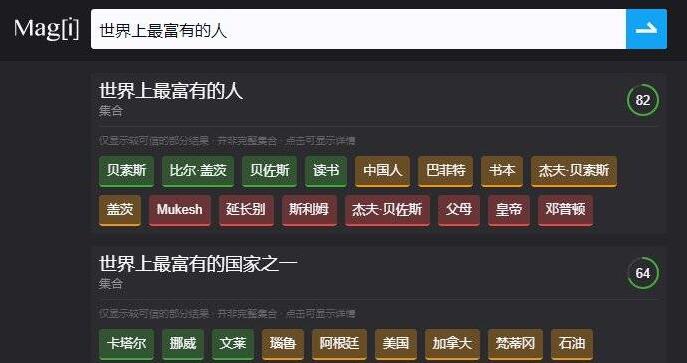
比如搜索“世界上最富有的人”时,我想要的是 Magi 能告诉我当前谁最富有,但它只能告诉我最富有的那一群人:
比如消歧义的把控,容易导致答案混乱(这一点季逸超自己在知乎上[1]也有所提到):

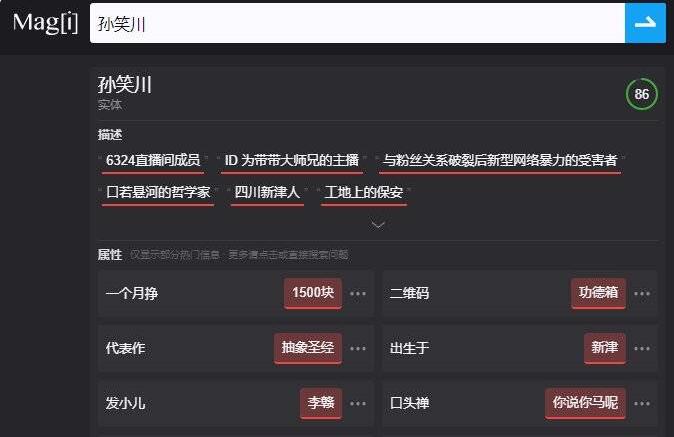
再比如,碰到一些实在太“复杂”的词条,magi.com 就凌乱了……
不过正如前面提到,这个搜索引擎并不是 Peak Labs 的最终产品——他们的真正目的,是借助搜索引擎背后 Magi 系统的力量,提供企业级的服务。
Peak Labs 的官网指出,他们希望未来的 Magi 系统能够成为“知识领域的 ImageNet”。它已经展示出的开放领域信息提取能力,可以应用到企业客户所在的细分领域内,变成一个更加强大的信息抽取系统,让每一个领域、每一家企业都可以轻松地打造属于自己的知识图谱。
“也许在不远的未来,伴随着整个行业的进步,Magi 所构建的包容万事万物的结构化网络,将成为通向可解释人工智能的基石。”Peak Lab 的网站这样写道。
——希望这个愿景能够实现。(就算实现不了也没关系啊!拿 magi.com 搜些奇怪的东西,还是能得到不少笑料的……)
如果你对 Magi 的技术细节感兴趣,可以点击下方“阅读原文”到 Peak Labs 网站进一步了解。季逸超在知乎的回答也做了更加详尽的阐述。
作者:杜晨 来源:硅星人















