在使用过多种爬虫软件后,终于找到一个简单易用且免费的数据采集器。对于编程基础不是很强的数据分析人员来说,爬一爬采集器简直像是量身定做。在使用过程中有几点感受必须大赞特赞。
免费 / 操作简单 / 跨平台 / 高效率
下面简单给大家介绍下使用方法,让更多人用最简单的方式采集到所需的数据。
首先爬一爬采集器的谷歌浏览器插件。
点击浏览器工具栏右侧按钮->更多工具->扩展程序。或在地址栏中输入chrome://extensions/
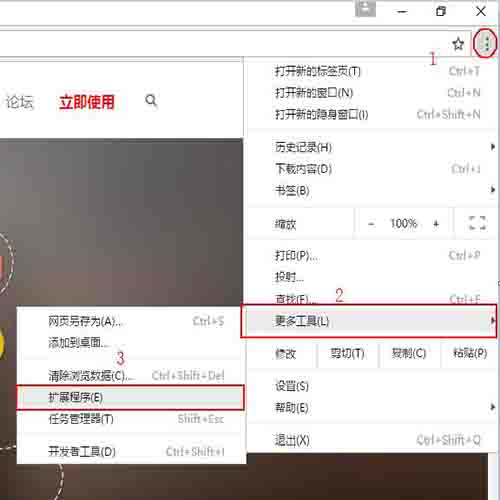
安装步骤2:打开扩展程序页面
3. 把下载好的插件拖入浏览器中“扩展程序”的页面,点击“添加扩展程序”,这样插件就安装完成了。“爬”标志出现在右侧插件栏。
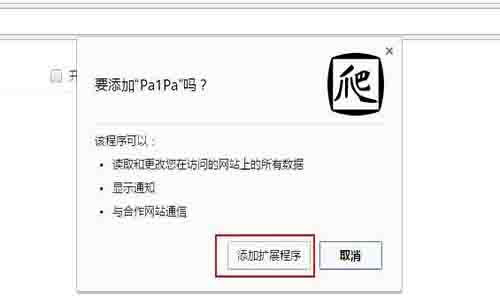
安装步骤3:添加扩展程序
4. 确保账号已登录,打开要采集的网站,点击浏览器插件栏的“爬”图标,启动插件。
5. 依次点击选取所要抓取的元素。如果色彩框没有包含所有的任务数据,点击所选元素右侧的“转换”按钮,切换算法,直到选中所有的任务数据。
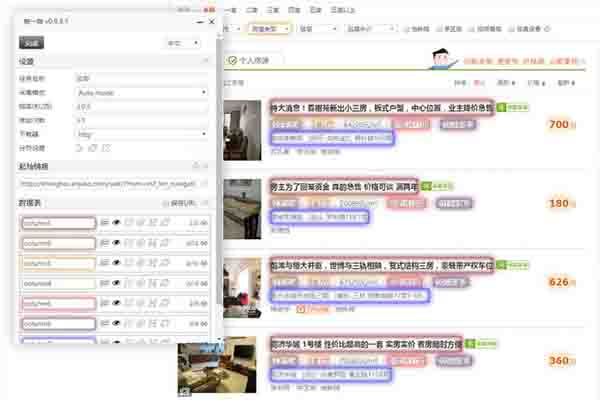
采集步骤1:依次选取要采集的元素
6. 如果要抓取多个页面,点击分页设置的箭头,选中页码所在的区域。
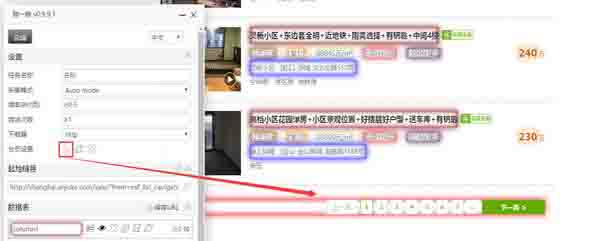
采集步骤2:选取页码所在的区域
7. 确认色彩框选中全部数据后,先点击“完成”按钮,再点击“测试”按钮,测试数据采集是否成功。(注:测试模式下最多抓取5页数据)
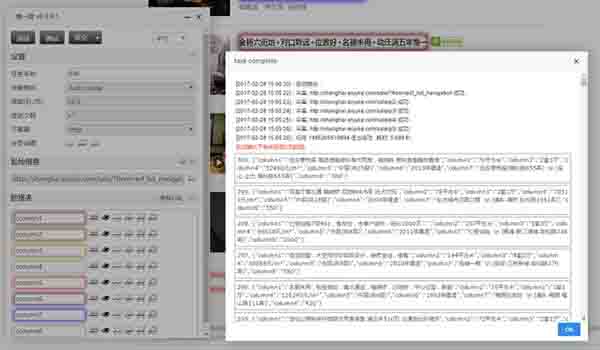
采集步骤3:测试数据
8. 确认测试成功后,点击”OK”关闭测试窗口。填写任务名称(长度为4-32的字符,必填),并根据个人需要修改列名。
9. 点击“提交”按钮,任务创建成功。您可在网站的“任务”页面下运行并管理该任务。

采集步骤4:运行任务
10. 在任务运行的同时,您可点击该任务的"管理"页面查看任务运行的状态及日志。
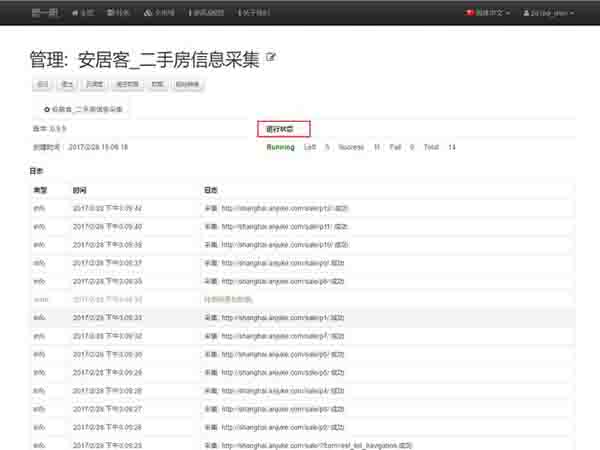
采集步骤5:查看任务运行状态
11. 任务运行结束后,点击"任务”页面的数据选项即可查看并下载数据。
采集步骤5:查看并下载数据
教程就简单给大家分享一下,操作很简单,又是免费的,功能也很强大。希望这次分享能给一些需要采集数据工作者或者需要数据支持的企业有所帮助!